The always-on tax
For a long time, our bottleneck was not code quality, model speed, or even tooling. It was that every meaningful step in the pipeline still required one human body to stay parked at one keyboard. If an implementation plan needed review, if a branch needed validation, if a draft pull request (PR) needed one more pass, the whole system quietly waited for us to be physically present.
That sounds manageable until you are the whole company. Lunch becomes a tiny project-management decision. A run becomes "dead time" because you are not there to answer the next question. Bedtime means the pipeline goes dark, not because the computer is done, but because you are.
That is the always-on founder tax. Your tools are powerful, but they still behave as if your attention is their power source. The exhausting part is not one dramatic interruption. It is the steady feeling of being on call for your own workflow.
So the useful question is not "How do we make AI faster?" It is: what changes when the computer no longer needs us present to do the work?
One note before we get into mechanics: this post assumes you are comfortable running commands in a terminal, and that you have a passing familiarity with GitHub — commits, branches, and pull requests. It does not assume you have used GitHub Copilot or any AI coding tool before. Every piece of jargon gets a definition on first use.
What a background agent actually is
Start with a concrete example. We can leave for lunch, dispatch a task, come back an hour later, and read the result. That only works because the task is not running in the same live conversation that is attached to our terminal.
GitHub Copilot CLI is a command-line tool — a text-based program you run in your terminal — that lets you dispatch AI agents to complete coding tasks. A background agent is one of those tasks.
In practice, a background agent is dispatched with mode: "background". The call returns immediately with an agent_id, which is just the identifier for that run. The work continues in a separate context window — think of it as a separate browser tab that the agent has open just for this task, with its own conversation history. Closing your terminal does not close that tab.
One prerequisite: the examples in this post use Foculoom's orqit Copilot CLI plugin for the orqit:conductor agent, the dev-session skill, and the /usage skill. Install it once with copilot plugin install orqit@foculoom, then run bash scripts/link-plugin-assets.sh to activate the skills. Without the plugin, the dispatch examples will fail. The list_agents(), read_agent(), and write_agent() calls are built into Copilot CLI and do not require any plugin.
That is different from sync mode, the default blocking mode where the terminal waits until the task finishes. In background mode, we can check in later instead of sitting there. list_agents() shows what is running, waiting, completed, or failed. read_agent() reads the result. write_agent() sends a follow-up message back into that agent if we want to unblock it or change direction.
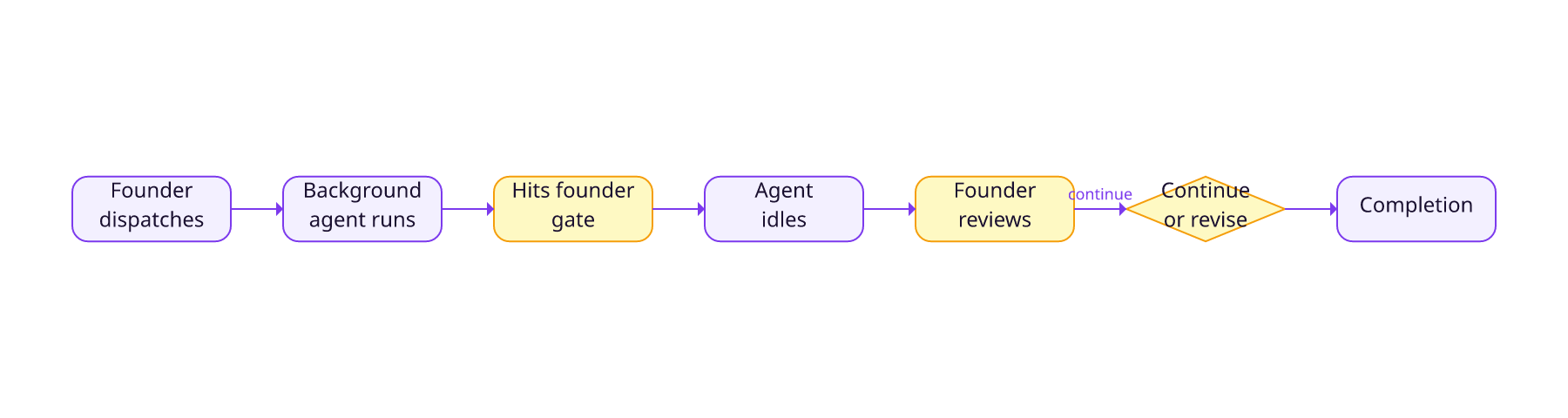
The important part is what a background agent is not. It is not a fire-and-forget black box. In our workflow it stops at decision gates and waits. We come back to evidence waiting for review, not a cursor hoping we never stood up.
task(
agent_type="orqit:conductor",
mode="background",
description="Implement auth bug fix",
name="fix-auth-bug",
prompt="Implement the scoped issue, follow the defined workflow, and stop at founder decision gates."
)Before lunch: the dispatch pattern
The before-lunch version is the easiest place to start because the time box is small and the cost of a mistake is low. We pick one scoped issue with clear acceptance criteria, meaning a concrete pass-fail list for the work. If the issue still has open questions, vague success language, or "TBD" fields, we do not dispatch it yet. Ambiguity is not something to outsource.
Before we send anything, we run dev-session — an orqit skill that acts as the session-start workflow. It checks the state of the repo, recent context, and whether we are resuming something or starting clean. It sounds procedural because it is. The quality of background work depends heavily on starting from a clean, explicit state.
Then we dispatch CONDUCTOR. CONDUCTOR is Foculoom's orchestrator agent: it manages the handoffs between three specialized roles. PLANNER writes the implementation plan. BUILDER writes and tests the code. REVIEWER checks whether the result is ready to ship. The reason for three roles rather than one is that each step is deliberately adversarial to the last: the reviewer's job is specifically to find what the builder missed, and the builder's job is to find what the planner underspecified. CONDUCTOR runs them in sequence and stops at named decision gates instead of guessing what we would approve.
task(
agent_type="orqit:conductor",
mode="background",
description="Implement auth expiry fix",
name="issue-1234-fix-auth-expiry",
prompt="Implement foculoom/foculoom-project#1234. Acceptance criteria are in the issue. Run PLANNER → BUILDER → REVIEWER. Stop at plan approval and ship/revise gates."
)Then we step away. For local runs, keep the machine awake — machine sleep can suspend the agent. For true away-from-machine durability, use /delegate instead, which runs in GitHub's cloud and survives a closed lid or powered-down machine.
When we come back, the pattern is simple. Run list_agents() to find the run, then read_agent(agent_id) to see what happened. If the status is idle, the agent is not stuck. It is waiting at a gate for us to review the plan or the PR evidence and decide what happens next.
The afternoon run: multi-step autonomy
Once the lunch-break pattern feels normal, longer absences become practical. A two-hour stretch away from the keyboard is enough time for a real multi-step workflow, not just one build or one review pass. That is where orchestration matters.
In our setup, CONDUCTOR always stops at four founder gates:
- Plan approval after PLANNER writes the implementation plan.
- Ship or revise after BUILDER prepares the PR and evidence.
- Money, legal, privacy, or other irreversible actions.
- Ambiguity that requires founder judgment.
That last point is why background work feels usable instead of reckless. The system does not try to role-play our preferences when the answer is unclear. It produces the best evidence it can, then waits.
When an agent has reached one of those gates, its status becomes idle. That means paused and waiting for the next message, not spinning, not hung, and not silently improvising. We can read only the new output with read_agent(agent_id, since_turn: N), review the result, and respond with write_agent(agent_id, "ship it") or write_agent(agent_id, "revise: tighten the scope and rerun tests").
The practical shift is subtle but important. We do not come back to a blinking terminal that still needs our presence to move. We come back to a completed chunk of thinking, code, or review that is already waiting for our judgment.
Sleeping through a pipeline run
Overnight runs use the same mechanics as a lunch break, but they only feel safe because the workflow is built to stop cleanly. The first safety mechanism is checkpointing. As the session grows, Copilot CLI can preserve progress instead of pretending infinite context exists. In plain terms, the run keeps its place instead of forgetting what it already figured out.
The second safety mechanism is that approval gates do not time out. If the agent reaches a founder gate at 1:13 a.m., it stays idle until morning. Nothing gets merged, deployed, or published just because we were asleep when the question came up.
One caveat on overnight local runs: keep the machine awake. Machine sleep can strand a local agent mid-run. If you want to close the lid and trust the system, use /delegate to run in GitHub's cloud instead.
The third safety mechanism is rule design. Our agents can draft PRs, push branches, and assemble evidence, but they do not auto-merge and they do not auto-deploy. That matters more at night than during the day. The whole point is to wake up to prepared work, not to surprises.
The fourth safety mechanism is context-budget discipline. AI models can only hold a certain amount of conversation history in memory at once — think of it as a rolling whiteboard that can only hold so many notes. A run that never cleans up its whiteboard eventually cannot add anything new. Checkpointing saves the important notes to a persistent store. Compacting summarizes and discards the rest, freeing space for the work still ahead. We keep the session lifecycle explicit so the agent does this housekeeping before it runs itself into a wall. That sounds mundane, but it is the difference between an orderly overnight run and a long confused transcript.
Morning review is usually incremental, not a full reread. list_agents() shows what is still running or waiting. read_agent(agent_id, since_turn: N) reads only what changed since the last check. If the run created draft PRs, gh pr list tells us what is now sitting there for review.
We have also learned not to ask overnight runs to solve open-ended strategy problems. They work best when the decision tree is shallow, usually two gates or fewer. If the work hits something genuinely unclear, the system does the right thing: it stops, documents the uncertainty, and waits.
Knowing it worked (and what it cost)
The shortest useful check is list_agents(). It shows the agent ID, the status, and whether unread output is waiting. If we just want a pulse check, read_agent(agent_id, wait: false) is enough. If we want to sit there until the run finishes, read_agent(agent_id, wait: true) blocks until it has an answer.
Cost matters too. Background agents use premium requests, meaning the billed calls to higher-capability Copilot models. The orqit /usage skill queries the Copilot billing API and reports current burn and remaining headroom, so we can check cost before a run and after it. This is distinct from the built-in Copilot CLI /usage command, which shows session metrics.
In practice our checklist is simple: list_agents() for status, read_agent() for results, and /usage for cost. If the work is going to become a habit, the cost has to be visible.
The guard rails that make this safe
This only works because the workflow is opinionated about where autonomy stops. We do not treat the system as magical. We treat it as powerful software that needs explicit limits.
First, non-trivial plans get an independent rubber-duck review before code is written. That is a separate pass whose job is to challenge the plan before anyone starts implementing it. Second, the anti-hallucination rules require evidence for factual claims. AI models have a structural tendency to generate plausible-sounding output that is factually wrong — inventing issue numbers, file paths, API behavior, or test results that do not exist. This is called hallucination, and it is a property of how the models work, not a bug that can simply be patched. The rules constrain what the agents are allowed to assert without evidence.
Third, there is no auto-merge and no auto-deploy path. Agents can prepare branches, draft PRs, and attach evidence, but the founder owns the irreversible step. Fourth, anything involving money, legal questions, privacy, or another irreversible action is an escalation point by design. The system stops and waits.
Fifth, version-control hygiene is a hard rule in the workflow itself. Agents are instructed never to push directly to the default branch, and all work moves through feature branches and reviewable pull requests. This is enforced by agent instructions, not a GitHub repository setting — which means it is only as reliable as keeping those instructions current. Sixth, mistakes are supposed to become durable improvements: acknowledged errors trigger a 5-whys post-mortem, a root-cause review that keeps asking why until the real failure mode is visible, and the fix gets written back to the tracking issue and the workflow artifacts.
The honest caveat is that none of these guard rails live in the laws of physics. They live in instructions, skills, hooks, and agent profiles. Those can drift. The value is not that the file exists. The value is that we keep it current enough for the rules to still mean something.
Your daily dispatch workflow
Before lunch
- Run
dev-sessionso the session starts from a known state. - Pick one issue with clear acceptance criteria and no open
TBDfields. - Dispatch
task(agent_type: "orqit:conductor", mode: "background", ...). - Step away, but keep the machine awake for a local run. If you want closed-lid durability, use
/delegate.
On return
- Run
list_agents()and find the relevant agent. - Run
read_agent(agent_id)to see the latest result. - If the status is
idle, review the plan or PR evidence and unblock it withwrite_agent(). - If the status is
completed, review the output and open the draft PR if one was created.
Before sleep
- Run the
dev-sessionend-of-session flow. - Check
git status --shortand make sure no tracked edits are left in limbo. - Only dispatch overnight work with shallow decision trees, ideally two gates or fewer.
- Keep the machine awake for a local overnight run, or use
/delegateif you want cloud durability.
Morning
- Run
list_agents()to see what is still running or waiting. - Run
read_agent(agent_id, since_turn: N)for an incremental morning read. - Run
/usageto see the premium-request burn from the run. - Run
gh pr listto see which draft PRs are waiting for review. - Run
dev-sessionagain before picking up the next chunk of work.
What compounds when you reclaim your hours
The payoff is not that we suddenly become willing to work all day and all night. It is the opposite. We get hours back that were previously lost to being physically present for work that did not actually require our live attention. Lunch becomes lunch again. Sleep becomes sleep again. The pipeline keeps moving, but we do not have to sit there and watch it move.
That compounds faster than it sounds. One reclaimed lunch break does not change a company. A few reclaimed hours every week starts to change how often we ship, how much context we lose, and how tired we feel while doing it.
The honest closing note is the same as the honest opening note: this only works when the inputs are good. Clear acceptance criteria, disciplined session lifecycle, and current instructions are not overhead here. They are the product. Background agents multiply good inputs. They do not rescue bad ones.
Questions or different experience with autonomous workflows? Reach out — we read every reply.